Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下:
1、可以在Python环境下写脚本 2、具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看。 3、支持多种数据库 4、支持定义任务优先级,自动重试链接。。。 5、分布式架构 等等优点。pyspider的设计基础是:以python脚本驱动的抓取环模型爬虫。
教程: http://docs.pyspider.org/en/latest/tutorial/
文档: http://docs.pyspider.org/ 发布版本: https://github.com/binux/pyspider/releases入门范例
from pyspider.libs.base_handler import *class Handler(BaseHandler): crawl_config = { } @every(minutes=24 * 60) def on_start(self): self.crawl('http://scrapy.org/', callback=self.index_page) @config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('a[href^="http"]').items(): self.crawl(each.attr.href, callback=self.detail_page) def detail_page(self, response): return { "url": response.url, "title": response.doc('title').text(), } 【插入图片,Pyspider界面】
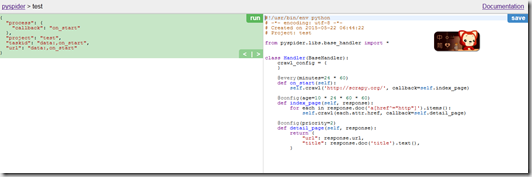
代码简单介绍
def on_start(self):
这是脚本的入口节点,当我们点击run的时候,程序会自动调用这个函数。self.crawl(url, callback=self.index_page):
这时最重要的API,将会添加新任务,大部分选项使用crawl的参数来指定。def index_page(self, response):
这个方法得到一个response对象,然后通过PyQuery的doc命令来解析。def detail_page(self, response):
返回一个dict对象作为结果。这个结果可以保存到数据库中。我们还可以在脚本中自定义函数或者对象。
【插入图片,运行界面】
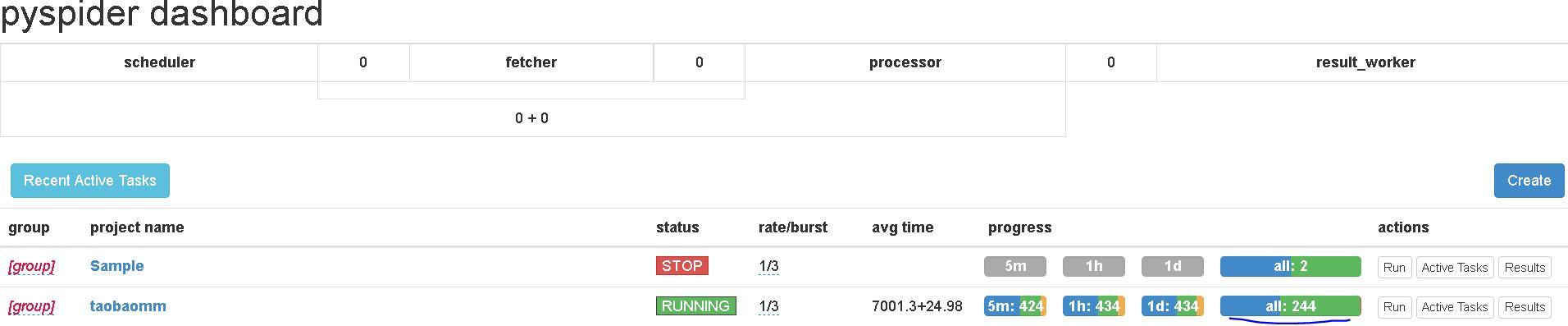
安装
推荐使用Pycharm,在Project Interpreter里面添加pyspider,目前最新的版本是0.3.9.
或者使用pip命令安装。今天来不及把整个项目内容讲完了,明天继续。